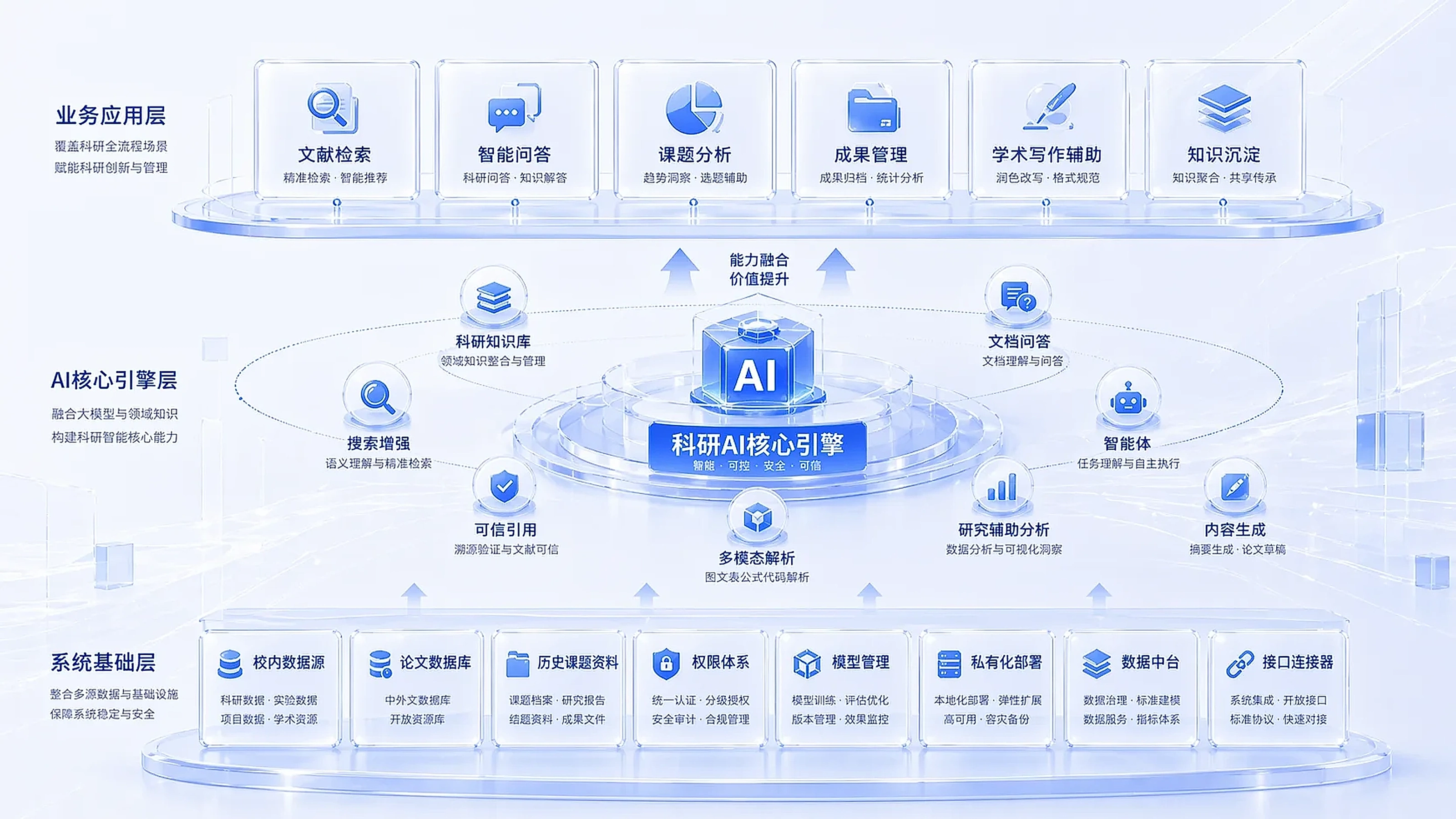
科研AI到底能干嘛?四个高校已落地的真实场景
科研AI不只是帮老师查查文献,真正落地的场景比大多数高校想象的要深得多。
我们帮好几所高校做AI落地的过程中,发现很多课题组对"AI能帮科研做什么"的理解还停留在"用ChatGPT聊天"的阶段。
实际上,搭好科研AI平台之后,能做的事情远比想象中多。
今天拆四个我们已经实际落地的科研AI场景,都是高校课题组真正在用的。
科研AI文献知识库
这是科研AI最基础也最刚需的场景。
很多课题组的痛点不是"找不到文献",而是"文献太多,看不过来"。一个材料科学方向的博士生,光跟自己课题相关的论文就有上千篇,每篇几十页,双栏排版还带大量图表和公式。
用通用AI工具做文献检索,最大的问题是"幻觉"——AI给你一个看起来很像回事的答案,但根本找不到原文出处。科研场景下,这种错误是不可接受的。
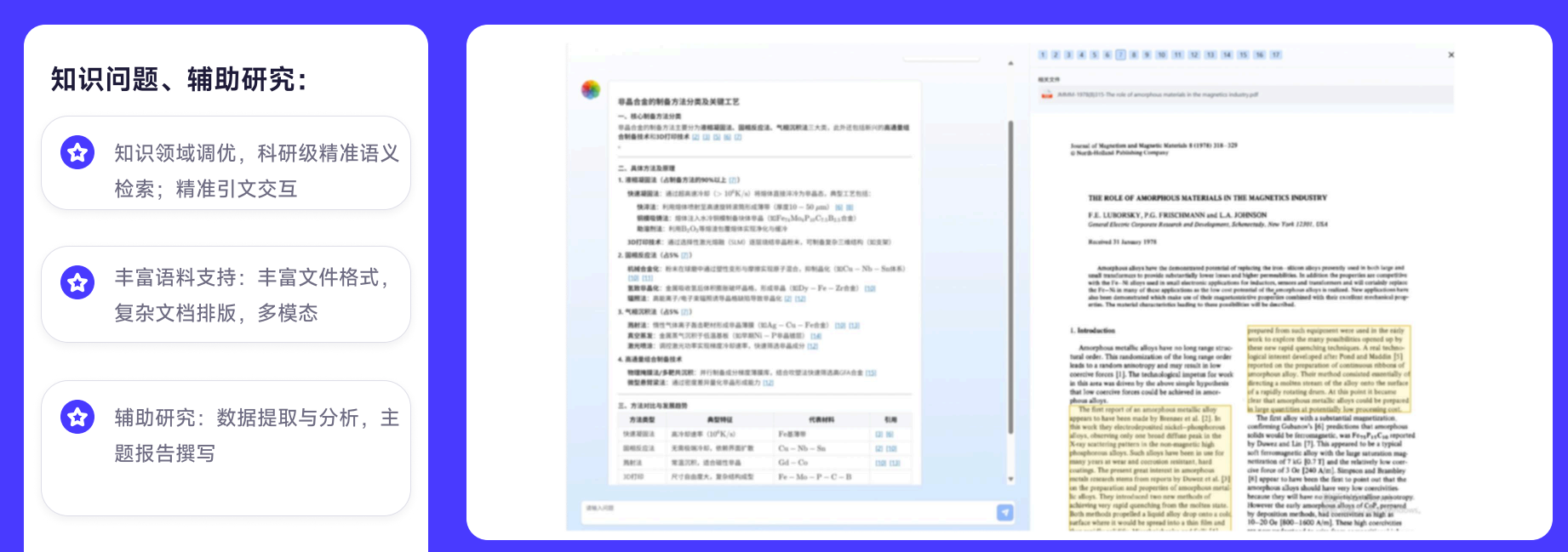
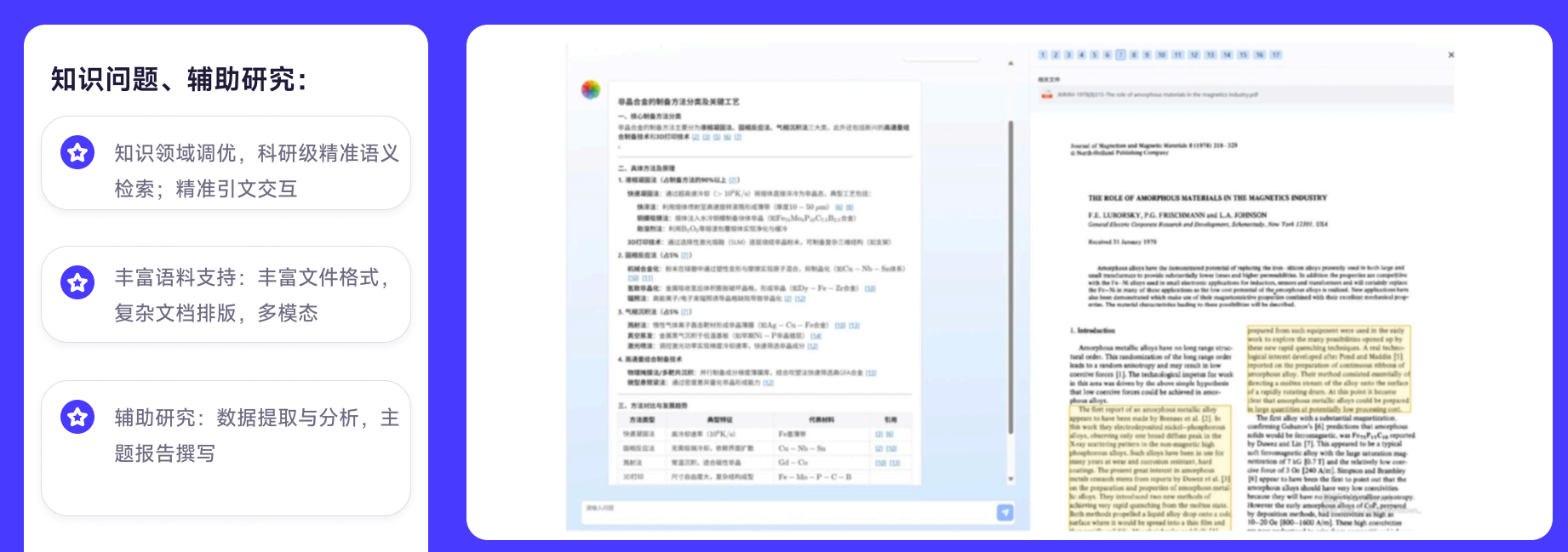
南京大学材料科学团队搭了科研AI知识库之后,每一条AI回复都可以溯源到具体的论文、具体的段落、具体的页码。
比如问"2024年关于铁基超导体的最新研究进展",AI不仅给出综述,还会标注"该结论来自XXX等人2024年发表于XXX期刊的论文第37页"。
这种带溯源能力的文献知识库,文献检索效率比传统方式提升了数倍,课题组内部的资料共享也从"各管各的文件夹"变成了统一平台。
科研AI专业术语识别
通用AI工具在科研场景有一个很要命的问题:专业术语识别不准。
理工科就不用说了,材料学、物理学、化学的术语密度极高,通用AI经常把相似概念搞混。文科也是,哲学、社会学、历史学的术语体系非常复杂,AI搞错一个词,整段论述就跑偏了。
这个问题是怎么解决的?
南京理工大学沈思教授团队最近刚开源了一个专门针对人文社科的学术大模型"兰章",就是用百亿级学术语料做深度训练,把跨语言环境下的低频专业术语识别准确率提升到了可用水平。
我们自己帮高校搭科研AI平台时也是同样的思路:先对基础模型做领域语料的持续预训练,让模型"学会"这个学科的语言体系,再基于课题组反馈做指令精调。
这个过程不复杂,但很关键。通用AI工具分不清"多铁性"和"铁电性"的区别,而领域适配后的AI可以。
科研AI实验参数预测
这个场景很多人觉得离自己很远,但其实已经在用了。
传统科研走的是"提出假设→设计实验→跑实验→看结果"的线性路径。一个问题可能要试几十组实验条件,每一组都要消耗时间和材料。
AI实验参数预测做的事情很简单:在跑实验之前,先让AI基于历史数据给出方向预判,帮课题组把试错范围缩小。
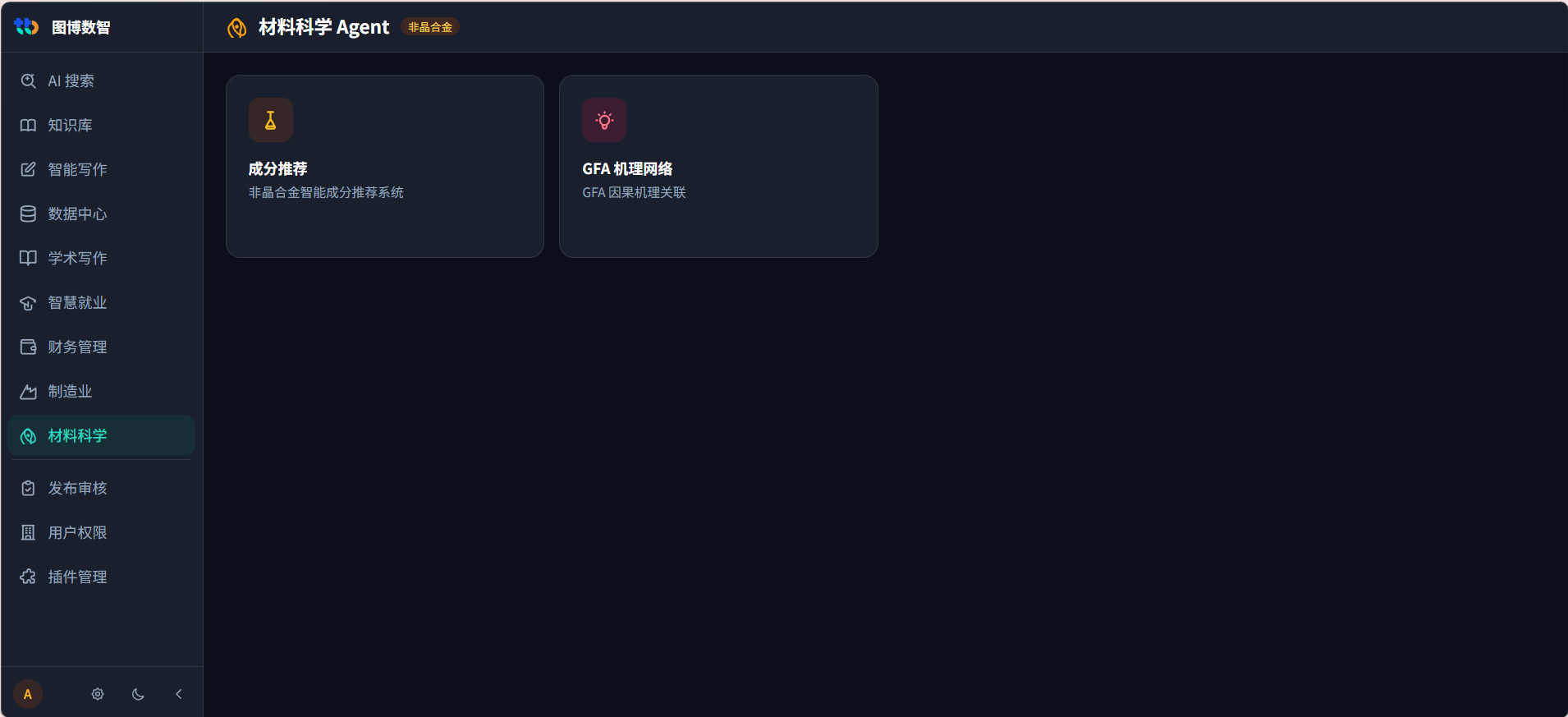
南京大学的MatSeek平台上就有这个能力。材料科学课题组输入目标性能参数,AI会推荐可能的配方组合和工艺条件,还会给出置信度。
这不是替代实验,而是帮课题组少走弯路。一组实验如果需要两周,AI预判帮你砍掉80%的无效方向,节省的时间非常可观。
科研AI材料发现
这个场景更前沿,但已经有真实案例了。
国内某前沿材料科学研究所跟图博数智联合建了一个数智创新联合实验室,核心目标之一就是用AI加速非晶合金的材料发现。
传统材料发现靠的是"试错法"——研究人员凭经验设计配方,做实验验证,不行就换一个再来。周期长,成本高,而且高度依赖个人经验。
AI介入之后,可以做性能推理和迭代验证:基于已知的材料数据库,AI自动推理出新配方的可能性能表现,给出推荐排序。研究人员从AI推荐的候选方案中挑选验证,大幅减少了盲目试错。
这个联合实验室的成果已经通过了同行评审验证。
材料发现的本质是"从海量可能中找到最优解",这恰恰是AI最擅长的事情。
科研AI落地的关键
跟企业AI一样,科研AI落地最重要的一步也是"先搞清楚痛点在哪"。
我们接触的高校课题组,需求差异非常大。有的课题组文献管理是核心痛点,有的实验数据挖掘是核心痛点,有的论文写作是核心痛点。
不要上来就想搭一个"什么都有的"AI平台。先选一个最痛的场景,做到位,让课题组真正用起来,再扩展到其他模块。
图博数智这几年帮南京大学、国内前沿科研院所、河海大学等高校和科研机构做了AI落地,每一个项目都是从调研课题组真实需求开始的,不是拿通用模板硬套。
我们图博数智这几年一直在帮企业和高校做AI落地的活儿,从AI知识库、智能体到私有化大模型部署,踩了不少坑也攒了不少经验。如果你所在的单位正在考虑AI落地,可以来我们官网看看实际案例和产品demo:**www.tubodata.com**,也可以直接加图老师聊聊。

