高校科研AI平台怎么搭?五个模块帮你理清思路
高校上AI,最怕的是"买了再说"——统一采购一个AI服务,给师生发账号,以为就完事了。
结果呢?数据全传到外部服务器,使用受频率限制和内容审查,科研场景的深度需求根本满足不了。最后师生还是各用各的,平台变成了摆设。
高校科研AI平台到底该怎么搭?今天把这个问题拆成五个模块,帮正在规划的高校理清思路。

第一个关键决策:自建还是采购
这是最根本的问题。
直接采购SaaS型AI服务,好处是上线快、成本低。但问题也很明显:
第一,数据安全不可控。师生的研究数据、未发表的论文、实验记录,全部传输到外部服务器。涉及涉密项目、国防研究、专利相关内容的课题组,这条路直接走不通。
第二,功能受限于服务商。公共AI服务有调用频率限制、内容过滤、功能阉割。科研场景需要的是灵活和深度,不是通用聊天。
第三,无法定制。不同学科对AI的需求完全不同——理工科要求数据分析和公式处理,文科要求长文本理解和文献综述,医科要求专业术语准确。一个通用AI服务满足不了这么多需求。
对高校来说,自建平台几乎是唯一靠谱的选择。 模型部署在校内服务器上,数据不出校,功能可以按需定制,不同学科可以有不同的工具配置。
成本也没有想象中高。现在开源模型的能力已经很强,一台配置合理的服务器就能支撑全校的基础使用。
模块一:AI文献助手
文献是科研的起点,也是AI最能发挥价值的环节。
AI文献助手要解决三个问题:
文献发现:基于研究主题自动推荐相关论文,支持跨数据库检索。不只是关键词匹配,而是语义层面的主题关联。
文献阅读:上传论文PDF,AI自动提取核心观点、研究方法、实验设计、结论和局限性。支持中英文论文,支持多论文对比阅读。
文献综述:基于选定的论文集合,AI辅助生成文献综述框架,包括研究脉络梳理、方法对比、研究空白识别。
但这里有一个必须注意的问题:AI生成的内容必须标注AI辅助。学术界对AI生成内容的规范越来越严格,平台需要提供溯源功能,让师生能追溯到每一条信息的原始论文。
模块二:AI数据分析
科研数据分析是AI的另一个高价值场景。
传统做法是:研究生学Python/R,写代码做数据清洗和统计分析,画图表写论文。这个过程很耗时,而且很多研究生的编程能力不够,在数据处理上花的时间比做研究本身还多。
AI数据分析模块可以做什么:
数据清洗和预处理:上传原始数据,AI自动识别数据质量问题(缺失值、异常值、格式不一致),建议处理方案。
统计分析:根据研究设计推荐合适的统计方法,自动运行分析并解释结果。t检验、方差分析、回归分析、非参数检验等常用方法全部覆盖。
数据可视化:根据数据特征自动推荐图表类型,生成符合学术发表标准的图表。
这个模块的关键是不替代研究者的判断。AI负责执行和辅助,研究问题的设计、方法的选择、结果的解释仍然由研究者完成。
模块三:AI写作辅助
学术写作是AI最容易"帮倒忙"的环节,也是最需要谨慎设计的模块。
AI写作辅助的正确用法不是"让AI写论文",而是:
写作润色:对已有的论文文本进行语法检查、用词优化、逻辑衔接改善。尤其是英文论文,AI的润色能力已经很接近专业编辑的水平。
格式规范:根据目标期刊的要求自动调整论文格式,包括引用格式、图表编号、页面设置等。
语言翻译:中英文学术写作的双向翻译。AI的学术翻译能力远超传统翻译工具,尤其是专业术语的准确性。
查重预检:在正式提交前,AI可以进行初步的查重分析,帮助作者识别和修改可能的重复内容。
严格限制:AI写作辅助模块必须明确禁止"代写"功能。平台应该在每篇使用AI辅助的文档上自动标注AI参与程度,确保学术诚信。
模块四:AI科研知识管理
科研过程中产生的大量知识——阅读笔记、实验记录、灵感想法、会议纪要——通常散落在笔记本、Word文档、微信收藏里。时间一长,自己写过什么都找不到。
AI科研知识管理模块要做的就是把个人和课题组的科研知识统一管理起来:
个人知识库:每个师生有自己的私有知识空间,上传的论文笔记、实验记录、思考碎片全部自动整理和标签化。需要的时候用自然语言搜索,AI直接返回相关内容。
课题组共享空间:课题组内的论文库、方法库、实验方案可以共享,AI根据成员的研究方向自动推送相关内容。
跨课题组知识发现:在学校范围内,AI可以发现不同课题组之间的研究关联,促进跨学科合作。
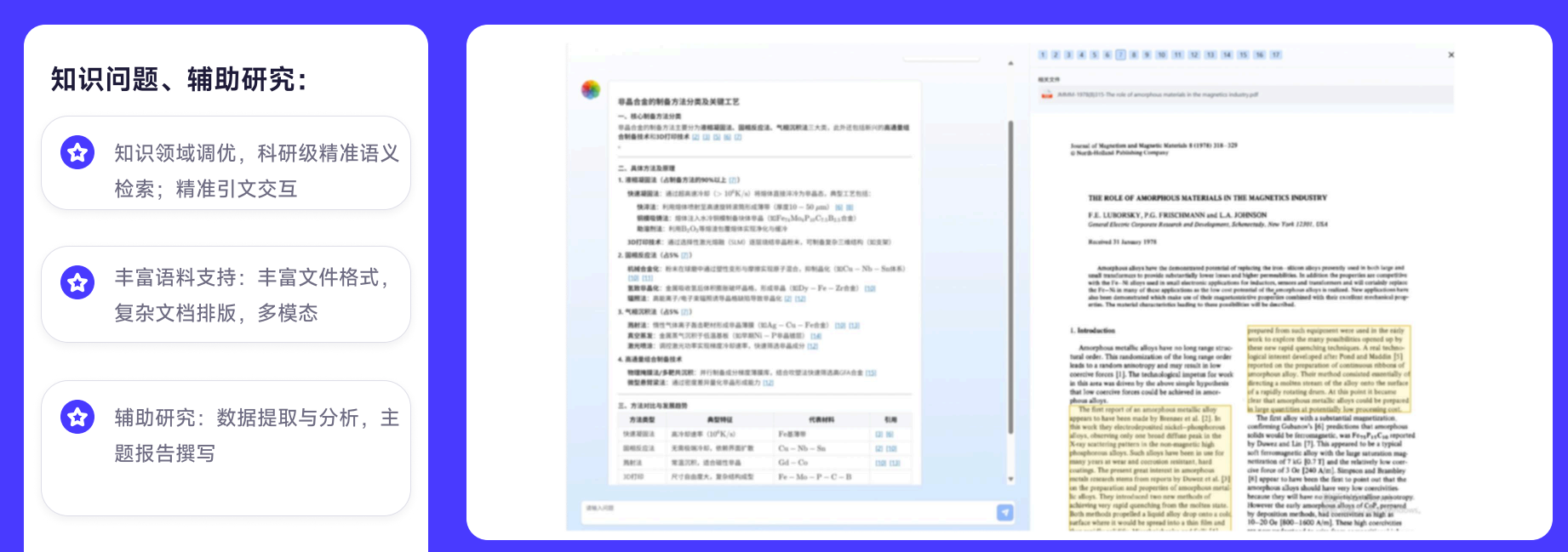
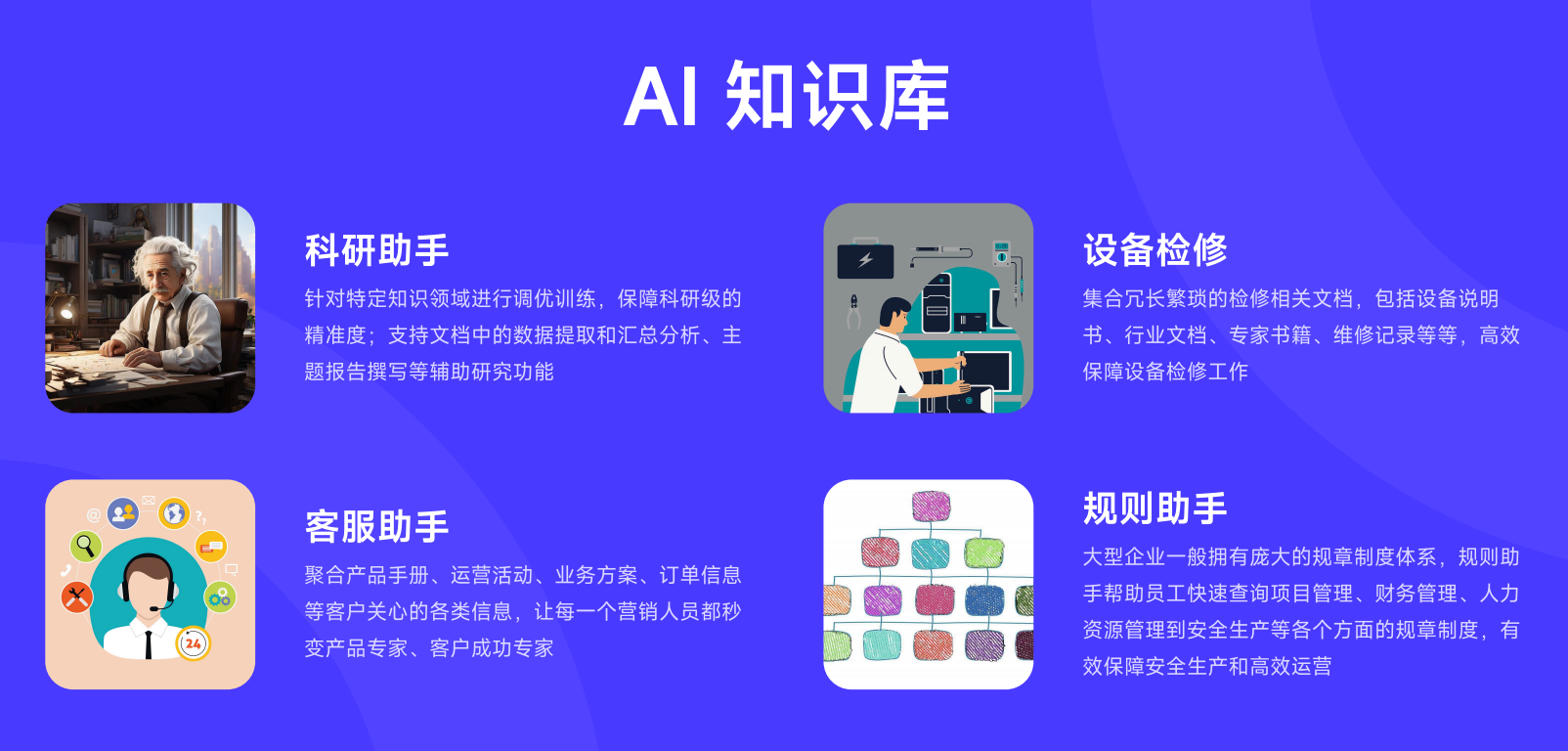
模块五:AI科研预测
传统科研走的是"提出假设→设计实验→验证结果"的线性路径,周期长、试错成本高。
AI科研预测模块做的事情,是在实验之前先给出方向预判,帮研究者把试错范围大幅缩小。
实验结果预测:基于已有的实验数据和研究文献,AI可以预测不同实验条件下的可能结果。比如材料科学领域,输入目标性能参数,AI推荐可能的配方组合和工艺条件。不是替代实验,而是减少无效实验的次数。
研究趋势预判:AI分析近几年的论文发表趋势、资助方向、会议热点,帮助课题组判断哪些研究方向正在升温、哪些已经饱和。对申请基金和确定研究方向有实际参考价值。
成果影响力评估:投稿之前,AI可以基于论文的创新性、方法新颖度、研究热度等维度,预估成果在不同期刊的接收概率和潜在引用量。
科研预测不是玄学,本质上是对已有数据的模式识别和趋势推演。
数据越扎实,预测越靠谱。 所以这个模块必须跟前面的AI数据分析和AI知识管理模块联动,有足够的数据基础,预测结果才有参考价值。
三个避坑建议
最后,基于我们帮高校做AI落地的实践经验,给三条建议:
第一,不要一次建成,分步走。
先搭好基础设施(私有化模型部署+统一身份认证),再做一个模块(比如AI文献助手),验证效果后再扩展到其他模块。一次想建完五个模块,最后大概率五个都做不好。
第二,让师生参与设计和测试。
AI平台是给师生用的,不是给信息中心看的。从设计阶段就邀请不同学科的师生参与,了解他们的真实需求。理科和文科对AI的需求完全不同,一个平台不可能一刀切满足所有人。
第三,私有化部署是底线。
高校科研数据的安全级别决定了必须走私有化部署。涉及涉密项目、未发表的科研成果,走公共AI服务是不可接受的。模型必须跑在学校自己的服务器上,数据不能出校园网。
我们图博数智这几年一直在帮高校做AI科研平台搭建,从私有化大模型部署到AI科研工具开发到系统集成,踩了不少坑也攒了不少经验。如果你所在的高校正在考虑建设AI科研平台,可以来我们官网看看实际案例和产品demo:**www.tubodata.com**,也可以直接加图老师聊聊。

